在 Uber,数据湖是支撑公司所有分析和机器学习的基础平台。过去,数据湖的摄取是通过批处理作业完成的,数据新鲜度以小时为单位衡量。随着业务需求向近实时洞察发展,我们重新设计了数据摄取流程,使其运行在 Apache Flink® 上,从而实现了更新鲜的数据、更低的成本以及 PB 级可扩展的运维能力。
过去一年,我们构建并验证了基于 Flink 的全新流式数据摄取系统 IngestionNext。我们已在 Uber 的一些大型数据集上验证了其性能,设计了可运行数千个作业的控制平面,并解决了流式数据摄取特有的挑战,例如小文件生成、分区倾斜和检查点同步。这篇博客将介绍 IngestionNext 的设计以及初步结果,这些结果表明,与批处理数据摄取相比,IngestionNext 能够显著提高数据新鲜度并显著提升效率。
为什么选择Streaming?
促使我们从批处理转向流处理的两个关键因素是:数据新鲜度和成本效益。
随着业务发展速度加快,Uber 的配送、乘客、出行、财务和市场营销分析部门不断要求获得更新鲜的数据,以支持实时实验和模型开发。批量导入数据会造成数小时甚至数天的延迟,从而限制了迭代和决策的速度。通过将数据导入迁移到 Flink 平台,我们将数据新鲜度从数小时缩短到数分钟。这一转变直接提升了模型发布速度、实验效率和分析准确性,惠及整个公司。
从成本效益的角度来看,Apache Spark ^™^批处理作业的设计本身就非常消耗资源。即使工作负载发生变化,它们也会以固定的时间间隔协调执行大规模分布式计算。对于 Uber 这样的规模——数千个数据集和数百 PB 的数据——这意味着每天需要运行数十万个 CPU 核心。流式处理消除了频繁批处理调度带来的开销,使资源能够以更平滑、更高效的方式随流量扩展。
架构概览
IngestionNext 摄取系统由多个层组成。
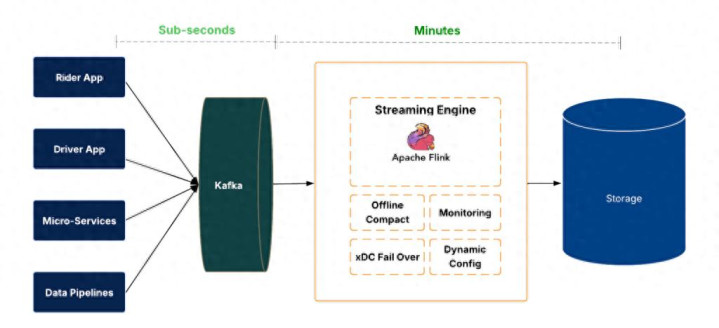
图 1:IngestionNext 架构。
在数据平面,事件到达 Apache Kafka® ^,^并由 Flink 作业消费。这些作业以 Apache Hudi ^™^格式写入数据湖,提供事务性提交、回滚和时间旅行功能。数据的新鲜度和完整性从源到目标端进行测量。
大规模数据摄取管理需要自动化。我们设计了一个控制平面,用于处理作业生命周期(创建、部署、重启、停止、删除)、配置变更和运行状况验证。这使得跨数千个数据集进行一致且安全的摄取成为可能。
该系统还设计有区域故障转移和回退策略,以确保可用性。发生故障时,数据采集作业可以跨区域转移或暂时以批处理模式运行,从而确保数据连续性和零数据丢失。
主要挑战和解决方案
小文件
流式数据摄取通常会生成大量小型 Apache Parquet ^™^文件,这会显著降低查询性能,并增加元数据和存储开销。当数据持续到达且必须近乎实时地写入时,这是一个常见的挑战。
传统的合并方法是逐条记录进行操作,需要先解压缩每个 Parquet 文件,将其从列式解码为行式,然后进行合并,最后再重新编码和压缩。虽然这种方法可行,但由于重复的编码/解码转换,计算量巨大且速度缓慢。
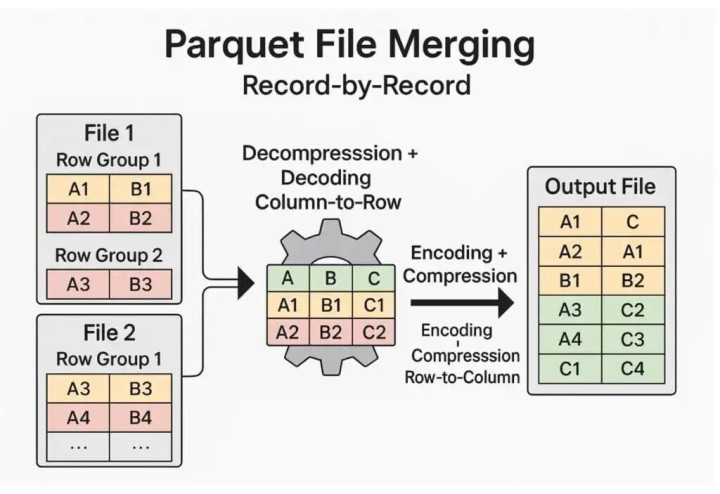
图 2:逐条记录合并 Parquet 文件。
为了克服这个问题,我们引入了行组级合并,它直接作用于 Parquet 的原生列式结构。这种设计避免了代价高昂的重新压缩,并将压缩速度提高了十倍以上。
像Apache Hudi PR [1]这样的开源项目探索了使用填充和掩码来对齐不同模式的模式演化感知合并,但这增加了大量的实现复杂性和维护风险。
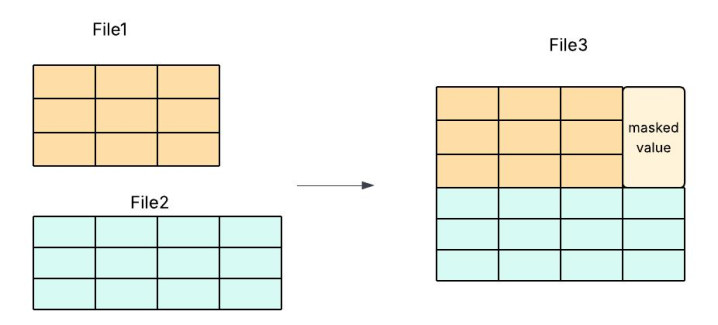
图 3:行组合并与数据掩码。
我们的方法通过强制执行模式一致性来简化流程——仅合并具有相同模式的文件。这消除了掩码或底层代码修改的需要,从而降低了开发开销,同时实现了更快、更高效、更可靠的压缩。
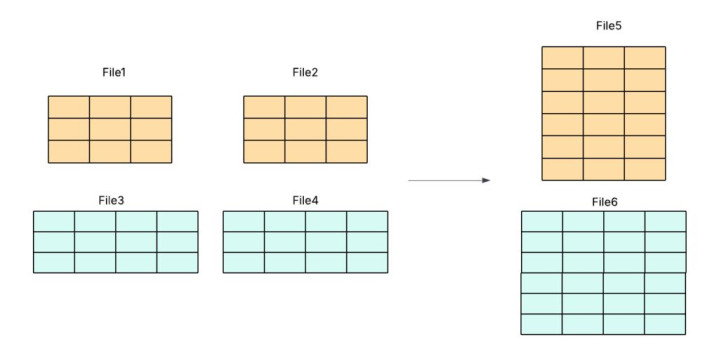
图 4:通过搜索模式简化行组合并。
分区倾斜
我们面临的另一个问题是,短暂的下游性能下降(例如垃圾回收暂停)会导致 Flink 子任务之间的 Kafka 数据消费不平衡。数据倾斜会导致压缩效率降低和查询速度变慢。
我们通过操作调整(使并行性与分区保持一致,调整提取参数)、连接器级别的公平性(轮询、对繁重分区暂停/恢复、每个分区的配额)以及改进的可观测性(每个分区的延迟指标、感知倾斜的自动扩缩容和有针对性的警报)来解决这个问题。
检查点和提交同步
我们还发现,Flink 检查点跟踪的是已消耗的偏移量,而 Hudi 提交跟踪的是写入操作。如果在故障期间它们发生错位,则可能会跳过或重复写入数据。
为了解决这个问题,我们扩展了 Hudi 提交元数据,使其嵌入 Flink 检查点 ID,从而在回滚或故障转移期间实现确定性恢复。
结果
我们将数据集迁移到基于 Flink 的数据摄取平台,并确认基于 Flink 的数据摄取能够提供分钟级的数据新鲜度,同时相比批处理方式,计算资源消耗降低 25%。以下是一个数据新鲜度提升的示例。
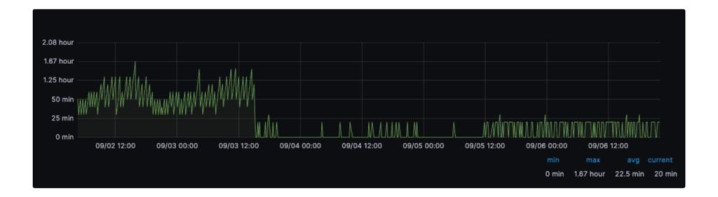
图 5:Streaming摄取前后对比
后续规划
我们通过 IngestionNext 显著降低了数据摄取延迟,实现了从在线 Kafka 到离线原始数据湖的批量摄取到流式摄取。然而,原始数据在下游的转换和分析环节仍然无法保证数据的新鲜度。为了真正加速数据更新,我们必须将这种实时能力扩展到端到端——从摄取到转换,再到实时洞察和分析。这一点在当下尤为重要。Uber 的数据湖为配送、出行、机器学习、乘客、市场、地图、财务和营销分析等部门提供支持,并将数据新鲜度作为这些领域的首要任务。大多数数据集都源自摄取环节,但如果没有更快的下游转换和访问速度,数据在决策时仍然会过时。这会对业务产生影响,涵盖实验、风险检测、个性化和运营分析等各个方面——过时的数据会延缓创新、降低响应速度,并限制企业做出主动的、数据驱动的决策的能力。
结论
从批处理到流式处理的转变标志着 Uber 数据平台演进的一个重要里程碑。通过在 Apache Flink 上重新架构数据摄取流程,IngestionNext 为 Uber 的 PB 级数据湖提供更新鲜的数据、更高的可靠性和可扩展的效率。该系统的设计强调自动化弹性和运维简易性,使工程师能够专注于构建数据驱动型产品,而不是管理数据管道。
对工程师而言,IngestionNext 的吸引力不仅在于其技术基础——流式数据摄取、检查点同步和容错控制平面——更在于其系统性的思维转变:将数据新鲜度视为数据质量的首要维度。IngestionNext 已在生产环境中得到验证,其下一个发展方向在于扩展流式 ETL 和分析功能,从而完善实时数据循环,赋能 Uber 的所有团队,使其能够更加自信地加速发展。
引用链接
[1]像Apache Hudi PR :https://github.com/apache/hudi/pull/13365
网上购买股票怎么开户提示:文章来自网络,不代表本站观点。